AI-powered Automation of the Order Reception Process
1. Abstract
AI-supported automation of business processes can now bring considerable economic benefits. In a recent article [1], we described how one of weyp’s customers reduced the cost of processing incoming orders by around 70%. Although everything was already digital beforehand, considerable human effort was still required. In this article, we take a closer look at the technology used to automate much of this previously “manual” work.
2. Initial situation / background
2.1. Manual work despite digitalization
Nowadays, orders no longer usually come in paper form. But even emails and PDF files are not “as digital” as we would like them to be: they are designed to be read and processed by humans – and are therefore difficult for “classic” software to understand. Thanks to AI, this is changing, as we will describe in more detail below.
There is still often a gap that people have to close with their work: between the digital but “unstructured” or “semi-structured” documents on the one hand, and the commercial application software (ERP, merchandise management system, CRM, …) on the other, where structured data is required. As a result, valuable employees spend a lot of time searching for data in (order) documents and then copying or typing it into input masks.
2.1. Artificial intelligence steps into the breach
“Artificial intelligence” (AI) has established itself as a collective term for a new type of digital information processing that – a bit like humans – can also process unstructured information. This also includes photos, audio data and video, but in this context (document processing) primarily texts. To achieve this, the AI processes a large number of indicators (“features”) in a quantitative manner that can be interpreted statistically.
The following table compares AI with classical, symbolic computer science.
| Symbolic | Statistical (AI) | |
| Type of data | structured and typified | any |
| Storage | databases | documents, multi-media files |
| Type of processing (calculation) | rule-based, comprehensible | numerical, impenetrably complicated |
| Computing effort | low | high |
| Basis of the algorithm | on the basis of exact human understanding | without an exact, detailed understanding of the interrelationships |
| Type of programming | explicit, high human effort | through training on data, lower human effort, higher computing effort |
| Type of results | structured | any (for analytical AI: structured; for generative AI: unstructured) |
| Reliability of the results | very high reliability (with error-free software) | mixture of correct and incorrect results |
| Human equivalent | cognitive / conscious process | intuitive / unconscious process |
This means for document processing
- Traditional methods require clear clues to find certain information, such as the phrase “delivery address:” above or to the left of the delivery address. AI makes it possible to find and extract information even if the context is variable and not known in advance. For instance, it might still find the right address even if it appears together with a text like “ship to” or “Lieferadresse” (a German translation of delivery address). Or if just the address itself is printed, without any explicit indication of its intended role.
- On the other hand, this leaves more room for error. In order to achieve the required process quality, the reliability of each individual piece of extracted information must be evaluated – with a so-called confidence. If the confidence is sufficiently high, the information is reliable and can be processed fully automatically. Otherwise, a human expert may have to at least check the case and possibly take over.
2.3. Does chatGPT – or generative AI – solve the problem?
Generative AI (“genAI”), i.e. specifically large language models (LLMs) such as those used in chatGPT, are therefore often not directly suitable for document processing. Even if they often answer questions (e.g. about a document) correctly, they also regularly make disturbing errors. Notorious in particular are so-called hallucinations (more precisely: confabulations) – freely invented assertions without foundation, which are expressed without a hint of doubt as if they were certain facts. This weakness of language models has not yet been eliminated. This makes the use of confidences all the more important in order to ensure quality.
A second weakness of generative language models is the nature of their results: namely prose. However, the aim of the processes discussed here is to capture structured data as required for further processing (execution of the order). An answer in prose would have to be analyzed again in order to extract the actual information and present it in a structured form. For example:
- Output of the LLM: “The customer orders an iPhone model 15 in blue.”
- Structured representation: article_vendor = “Apple”; article_name = “iPhone 15”; article_color = “blue”
There are several possible solutions to this problem, but we will not go into them in detail here.
In summary, it can be said that generative language models are less useful for extracting information from documents than one might expect due to their eloquence. They can be used for this purpose, but not in the sense of a complete solution, but only as a partial step that must be supplemented by further – then symbolic – steps. And this is exactly what weyp’s solution offers.
3. The technology from weyp
3.1. Technological requirements
A good solution for capturing information from documents must fulfill several requirements:
- Flexibility: Documents created by humans do not adhere slavishly to specifications, and certainly not down to the level of characters. This presents traditional computer science with difficult tasks and makes the use of AI necessary.
- Accuracy / reliability: Customers expect to receive exactly the items they have ordered. Approximate fulfillment of the order – similar sounding items, different quantities, etc. – are not an option. The results of the information extraction must therefore be correct or marked as to be checked.
- Integration: The results must be structured, i.e. accessible to proven symbolic processing by precisely working systems such as ERP, merchandise management systems, etc. In addition, the feed into the target systems should be automatic.
With the paipz platform [2], weyp offers a whole range of such solutions: Not only for incoming orders, but also for other use cases such as recording tax assessments or analyzing sales contracts.
3.2. The modular structure of paipz®
The foundation for paipz’ versatility is its modular structure.
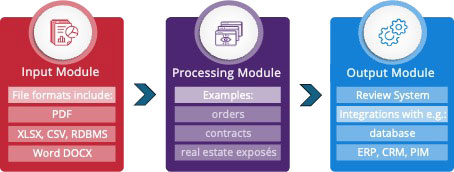
There are three types of modules:
- Input modules via which paipz can accept documents from existing systems. For example, a connector to the e-mail server can be used to accept orders. A potentially important feature is a “classifier” that decides which documents should be processed at all. For example, cancellations or queries could also be received in the mailbox, which of course should not (directly) result in an order.
- The processing module that maps the use case – in this case “order acceptance”. By default, it also includes the visual display of results that are not sufficiently confusing, which can therefore be checked and, if necessary, corrected by human employees.
- Output modules through which the structured data is fed into one or more target systems. As with the input modules, weyp can develop customer-specific modules if required, e.g. for connection to the company’s own, self-developed merchandise management system.
The modular structure makes it easy to adapt to the individual circumstances and requirements of each customer. It also makes it easier to adapt the solution when new technology becomes available. This allows users to benefit conveniently and cost-effectively from rapid progress in AI research.
4. Order processing with paipz® from weyp
4.1. The peculiarities of orders
The following configuration was used for the specific application described in [1]. The input module is connected to the customer’s (rather specialized) email system. It analyzes the main text of each email as well as the attachments that potentially contain order information. Emails with concerns other than orders are recognized and “rejected” (i.e. not processed further in the paipz “Orders” module – although processing by another module would of course be possible).
The orders themselves are analyzed separately by file format. The most important format, accounting for around two thirds of the volume, is PDF. The information is almost always semi-structured like a typical letter:
- The identity of the orderer (company, contact person, address) is shown at the top in the “Sender” field.
- Order number, delivery address, date and the like are sometimes grouped in a table, sometimes spread across the page(s).
- The ordered items themselves are listed as a table. However, the selection, designation and arrangement of the columns varies.
Accordingly, we use different technologies to find and extract the relevant information. For example, the address field can be reliably found using a very “small”, specialized AI – much more cost-effective and also more reliable than LLMs. The fine-grained structuring of the information contained is in turn largely carried out using classic computer science.
You might think that displaying the articles as a table would make extracting them particularly easy. But the opposite is the case, as we will see in a moment.
4.2. Challenges, exemplified for table extraction
As described above, the tables have a high degree of content variability. It is therefore important to recognize which column contains which information. For example, whether a column called “Article” contains an article number (EAN? Or the number in the company catalog?), or a name of the article (official designation or informal variant? With manufacturer’s name or without? German or English?).
AI helps with this – specifically, modern LLMs, for example, have proven to be very helpful for this, also because they can be used for various use cases without complex adaptations. Before such universally pre-trained LLMs were available, we used more specialized AI models that were only trained and competent for one use case at a time.
But the difficulties with tables start earlier. Here is an (incomplete) list of sub-problems that need to be solved:
- Recognition of tables in the document; differentiation between similar structures with different semantics
- Recognition of substructures: rows, columns, column headers, row blocks, cells, merged cells
- multiline cells
- Correct handling of “unconventional” structures, e.g.
- Overlapping columns
- Columns with several fields arranged one below the other
- “Tables in tables”: the content of cells is organized in tabular form
- Page breaks within the table or even within a table row
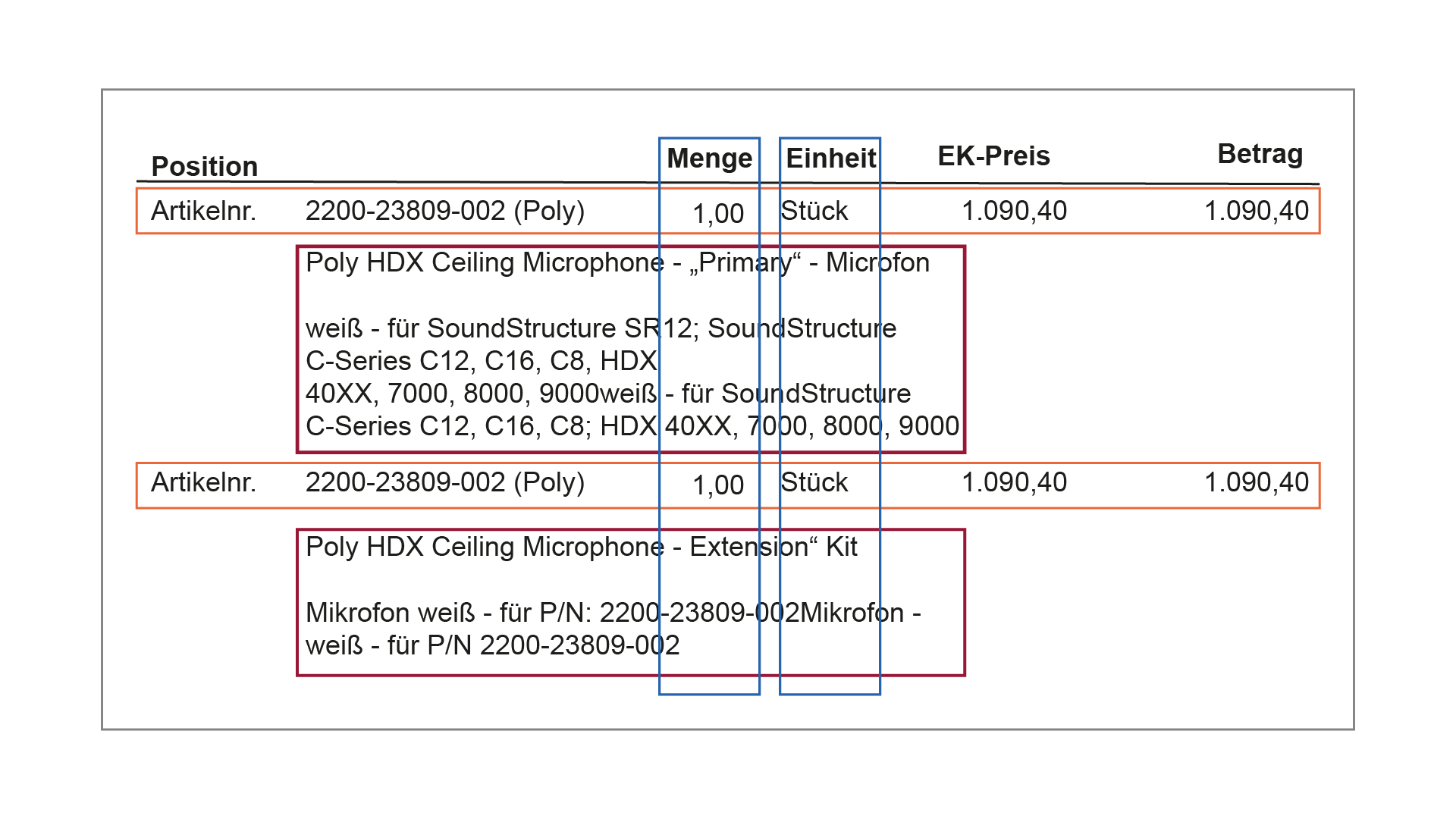
We see all of these challenges (and more) in incoming orders; the authors are often amazingly creative. To illustrate, here are two real-life examples from one of our clients’ incoming orders.
What looks like a normal table at first glance deviates in at least four points from a clear, grid-like structure with column naming. The position is missing, despite the column being named accordingly. Columns for article number and description, on the other hand, exist but are not named. The article descriptions run into the columns for quantity and unit. Finally, the “columns” for article number and description are arranged below each other rather than next to each other.
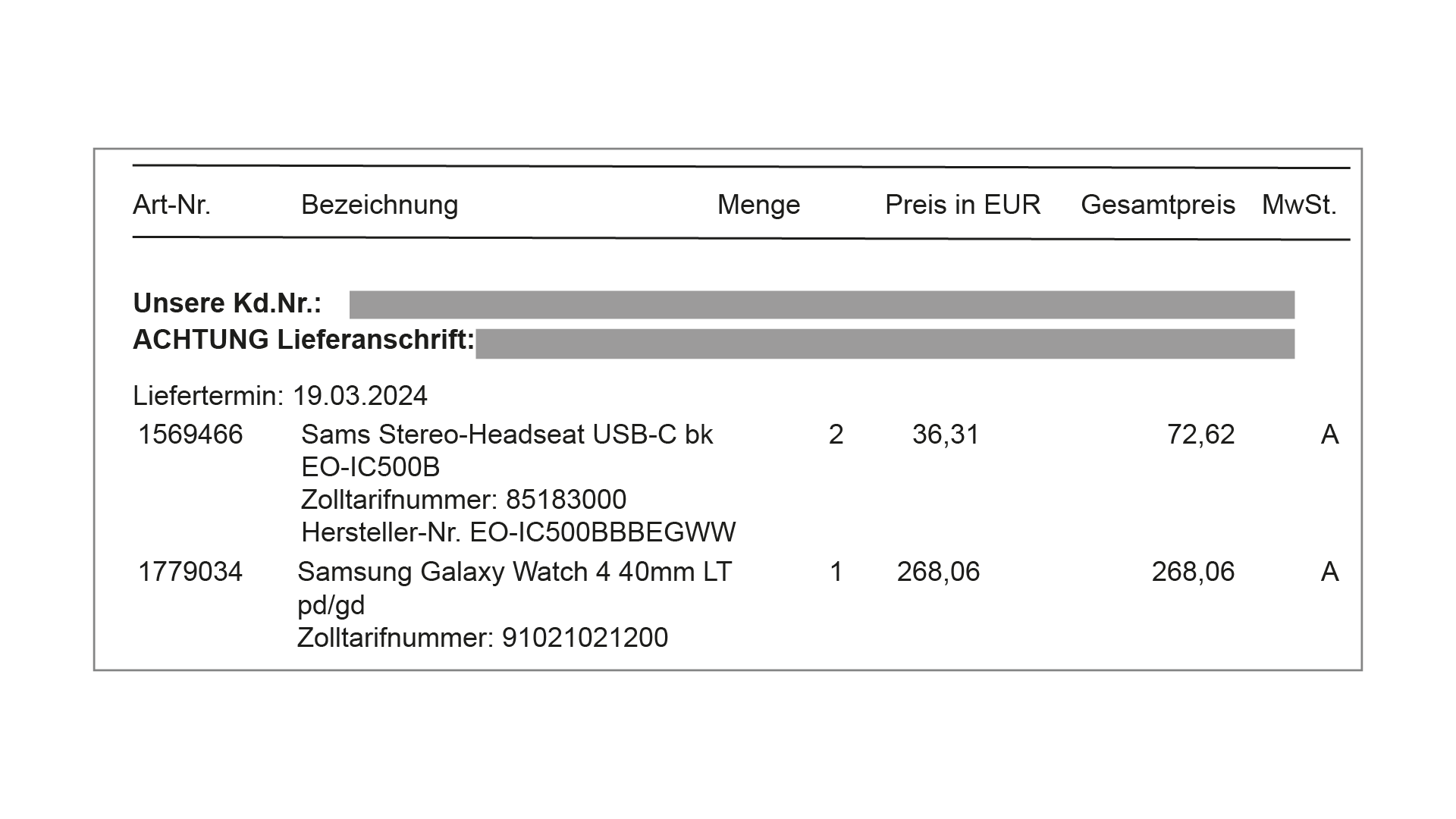
In the second example, the table is interrupted by delivery information. Due to such problems, which occur in an unpredictable number of variations, “classically” programmed algorithms for table extraction (such as the Python library “camelot” or “tabula”) regularly fail in practice.
4.3. Technology example: table recognition
As an example, we will go into more detail about our technology for recognizing tables below: First, a table must be recognized or localized as such. Various approaches are conceivable and, depending on the specific document, suitable for this. Among other things, our employees have developed a method based on image processing (computer vision, CV) and one that works purely textually (using an LLM).
The image processing approach is quite general: it can also be used to recognize other design elements in documents, e.g. graphics, headings, paragraphs. For this purpose, many examples of such elements are virtually marked in a corpus of documents by drawing a rectangle around them. Then an established model for visual recognition is trained on this data. The best models today are convolutional neural networks (CNNs) or detection transformers (DETR). We use CNNs from the “YOLO” series [3], with which we achieve very high accuracy with moderate consumption of computing power.
LLMs are also versatile, but the processing of tables often requires some additional work (e.g. [4]). A key technology for this is “RAG” (retrieval-augmented generation), which provides the LLM with the documents or document fragments that are needed to answer a question. On the one hand, this can prevent “hallucinations” with which the LLM fills gaps in its knowledge base. In connection with tables, however, it is particularly important that RAG can also be used to omit a lot of irrelevant information. Such information can easily “distract” or “confuse” an LLM, i.e. lead to poor or incorrect answers. It therefore often makes sense to split a document into sections and feed the LLM only one table as input in order to extract data from this table. But even then, LLMs are more suitable for extracting individual values from the table. However, in order acceptance, as in many other applications, it is necessary to prepare the table as a whole for symbolic processing. weyp has therefore developed its own approach that implements this using LLMs.
Depending on the type of document, the design of the table, the language and meaning of the content and the requirements of the application, one or the other approach may be more suitable. Several approaches can even be combined to achieve maximum automation and reliability. Confidences are extremely helpful here.
5. Conclusions
We can summarize the following findings:
- Extracting structured data from documents cannot be solved well with chatGPT or similar generative language models (alone).
- Instead, it is advisable to combine different types of AI (analytical and generative; language models and image processing) and symbolic (classical) algorithms.
- All algorithms must quantify the reliability of their results (with “confidence” values); in case of doubt, they must be easy to check by humans.
- A wide range of applications and openness to the future are made possible by a modular architecture.
In this way, processes can be automated, employees can be relieved and users and customers can continue to be offered the required high quality.
6. References
- Efficient order processing: from manual processes to AI-supported automation; 2024. https://medium.com/@harmonious_beige_minnow_591/document-understanding-order-management-ded1e8689d57
- Paipz; 2024. https://paipz.com
- YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors; 2022. https://arxiv.org/abs/2207.02696
- PDF Hell and Practical RAG Applications, 2024. https://unstract.com/blog/pdf-hell-and-practical-rag-applications/


13 Comments