KI-gestützte Automatisierung der Bestellannahme
1. Abstract
Die KI-gestützte Automatisierung von Geschäftsprozessen kann inzwischen erhebliche wirtschaftliche Vorteile bringen. In einem kürzlich erschienenen Artikel [1] haben wir beschrieben, wie ein Kunde von weyp die Kosten für die Bearbeitung eingehender Aufträge um rund 70% gesenkt hat. Obwohl bereits vorher alles digital ablief, war noch ein erheblicher menschlicher Aufwand erforderlich. In diesem Artikel werfen wir einen genaueren Blick auf die Technologie, mit der ein großer Teil dieser zuvor „manuellen“ Arbeit automatisiert wurde.
2. Ausgangslage / Hintergrund
2.1. Manuelle Arbeit trotz Digitalisierung
Heutzutage kommen Bestellungen normalerweise nicht mehr in Papierform. Aber auch E-Mails und PDF-Dateien sind nicht „so digital“, wie man es sich wünscht: sie sind darauf ausgelegt, von Menschen gelesen und verarbeitet zu werden – und dementsprechend schwerverständlich für „klassische“ Software. Dank KI ändert sich das gerade, wie wir unten detaillierter beschreiben werden.
Noch besteht oft eine Lücke, die Menschen mit ihrer Arbeit schließen müssen: zwischen den digitalen aber „unstrukturierten“ oder „semistrukturierten“ Dokumenten einerseits, und der kaufmännischen Anwendungssoftware (ERP, Warenwirtschaft, CRM, …) auf der anderen Seite, wo strukturierte Daten erforderlich sind. So kommt es, dass kostbare Mitarbeiter viel Zeit damit verbringen, Daten in (Bestell-)Dokumenten zu suchen und dann in Eingabemasken zu kopieren oder abzutippen.
2.1. Künstliche Intelligenz springt in die Bresche
„Künstliche Intelligenz“ (KI) hat sich als Sammelbegriff für eine neue Art der digitalen Informationsverarbeitung etabliert, die – ein bisschen wie Menschen – auch unstrukturierte Informationen verarbeiten kann. Dazu gehören auch Fotos, Audiodaten und Video, aber in diesem Kontext (Dokumentverarbeitung) vor allem Texte. Um das zu leisten, verarbeitet die KI eine große Anzahl von Indikatoren („Features“) in einer quantitativen Weise, die statistisch interpretiert werden kann.
Die folgende Tabelle stellt KI der klassischen, symbolischen Informatik gegenüber.
|
Symbolisch
|
Statistisch (KI) | |
| Art der Daten | strukturiert und typisiert | beliebig |
| Speicherung | Datenbanken | Dokumente, Multi-Media Dateien |
| Art der Verarbeitung (Berechnung) | regelbasiert, nachvollziehbar | numerisch, undurchschaubar kompliziert |
| Rechenaufwand | niedrig | hoch |
| Grundlage des Algorithmus | auf Basis exakten menschlichen Verständnisses | ohne exaktes, detailliertes Verständnis der Zusammenhänge |
| Art der Programmierung | explizit, hoher menschlicher Aufwand | durch Training auf Daten, geringerer menschlicher Aufwand, höherer Rechenaufwand |
| Art der Ergebnisse | strukturiert | beliebig (bei analytischer KI: strukturiert; bei generativer KI: unstrukturiert) |
| Verlässlichkeit der Ergebnisse | sehr hohe Verlässlichkeit (bei fehlerfreier Software) | Mischung von korrekten und inkorrekten Ergebnissen |
| Menschliche Entsprechung | kognitiver / bewusster Prozess | intuitiver / unbewusster Prozess |
Für die Dokumentverarbeitung bedeutet das:
- Klassischen Methoden setzen eindeutige Hinweise voraus, wie z.B. das Wort „Aktenzeichen“ gefolgt von einem Doppelpunkt, um das Aktenzeichen zu finden. KI ermöglicht es, auch dann Informationen zu finden und zu extrahieren, wenn der Kontext variabel und nicht im Vorhinein bekannt ist.
- Auf der anderen Seite ist dadurch mehr Raum für Fehler. Um die erforderliche Prozessqualität zu erreichen, muss die Verlässlichkeit jeder einzelnen extrahierten Information – mit einer sogenannten Konfidenz – bewertet werden. Bei hoher Konfidenz ist die Information verlässlich und kann voll automatisiert weiterverarbeitet werden. Andernfalls muss möglicherweise ein menschlicher Experte den Fall zumindest prüfen, ggf. übernehmen.
2.3. Löst ChatGPT – bzw. generative KI – das Problem?
Generative KI („genAI“), also konkret große Sprachmodelle (large language models, LLMs) wie sie in chatGPT zum Einsatz kommen, sind deshalb oft nicht direkt tauglich für die Dokumentverarbeitung. Auch wenn sie Fragen (z.B. zu einem Dokument) oft richtig beantworten, so leisten sie sich auch regelmäßig verstörende Fehler. Berüchtigt sind insbesondere sogenannte Halluzinationen (exakter: Konfabulationen) – frei erfundene Behauptungen ohne Grundlage, die ohne den Anflug eines Zweifels wie sichere Fakten versprachlicht werden. Diese Schwäche der Sprachmodelle konnte bis heute nicht beseitigt werden. Umso wichtiger ist die Verwendung von Konfidenzen, um die Qualität zu sichern.
Eine zweite Schwachstelle der generativen Sprachmodelle ist die Art ihrer Ergebnisse: nämlich Prosa. Ziel der hier besprochenen Prozesse ist aber die Erfassung strukturierter Daten, wie sie für die weitere Verarbeitung (Ausführung der Bestellung) erforderlich sind. Eine Antwort in Prosa müsste ihrerseits nochmals analysiert werden, um die eigentliche Information zu entnehmen und strukturiert dazustellen. Als Beispiel:
- Ausgabe des LLMs: „Der Kunde bestellt ein iPhone Modell 15 in blau.“
- Strukturierte Repräsentation: artikel_name = „iPhone 15“; artikel_farbe = „blau“
Für dieses Problem gibt es mehrere Lösungsansätze, auf die wir an dieser Stelle aber nicht im Detail eingehen.
Zusammenfassend kann man sagen, dass generative Sprachmodelle für Informationsextraktion aus Dokumenten weniger nützlich sind, als man Aufgrund ihrer Eloquenz vermuten könnte. Sie können für diesen Zweck eingesetzt werden, aber nicht im Sinne einer fertigen Lösung, sondern nur als Teilschritt, der um weitere – dann symbolische – Schritte ergänzt werden muss. Und genau das bietet die Lösung von weyp.
3. Die Technologie von weyp
3.1. Technologische Anforderungen
Eine gute Lösung für die Informationsaufnahme aus Dokumenten muss mehrere Anforderungen erfüllen:
- Flexibilität: Von Menschen erstellte Dokumente halten sich nicht sklavisch an Vorgaben, und schon gar nicht bis hinab auf die Ebene von Zeichen. Das stellt klassische Informatik vor schwer lösbare Aufgaben, und macht den Einsatz von KI erforderlich.
- Genauigkeit / Verlässlichkeit: Kunden erwarten, genau die Artikel zu erhalten, die sie bestellt haben. Approximative Ausführung des Auftrags – ähnlich klingende Artikel, andere Anzahlen, etc. – sind keine Option. Die Ergebnisse der Informationsextraktion müssen daher korrekt sein, oder als zu überprüfen markiert werden.
- Integration: Die Ergebnisse müssen strukturiert sein, also bewährter symbolischer Verarbeitung durch exakt arbeitende Systeme wie ERP, Warenwirtschaftssystem etc. zugänglich. Zudem soll die Einspeisung in die Zielsysteme automatisch erfolgen.
Mit der Plattform paipz [2] bietet weyp gleich eine ganze Palette solcher Lösungen: Nicht nur für den Bestelleingang, sondern auch für andere Anwendungsfälle wie z.B. die Aufnahme von Steuerbescheiden oder die Analyse von Kaufverträgen.
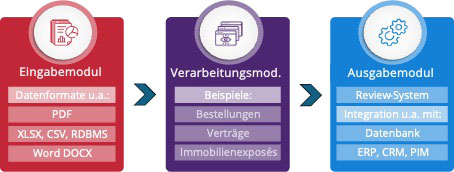
3.2. Die modulare Struktur von paipz®
Die Basis für die Vielseitigkeit von paipz® ist sein modularer Aufbau.
Es gibt drei Arten von Modulen:
- Eingabemodule, über die paipz® von existierenden Systemen Dokumente annehmen kann. Für die Bestellannahme kommt z.B. ein Konnektor zum E-Mail-Server in Frage. Ein potenziell wichtiges Feature ist ein „Klassifikator“, der entscheidet, welche Dokumente überhaupt verarbeitet werden sollen. Z.B. könnten im Postfach auch Stornierungen oder Rückfragen eingehen, die natürlich nicht (direkt) in einer Bestellung resultieren sollen.
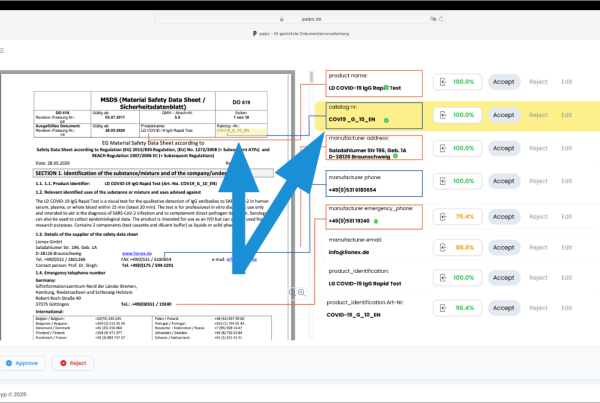
- Das Verarbeitungsmodul, das den Anwendungsfall abbildet – hier „Bestellannahme“. Es beinhaltet standardmäßig auch die visuelle Darstellung von nicht ausreichend konfidenten Resultaten, die somit durch menschliche Mitarbeiter geprüft und ggf. korrigiert werden können.
- Ausgabemodule, durch die die strukturierten Daten in ein oder mehrere Zielsysteme eingespeist werden. Wie bei den Eingabemodulen kann weyp bei Bedarf kundenspezifische Module entwickeln, z.B. für die Anbindung ans firmeneigene, selbstentwickelte Warenwirtschaftssystem.
Die modulare Struktur erlaubt die einfache Anpassung an die doch meist recht individuellen Umstände und Anforderungen jedes Kunden. Zudem erleichtert sie es, die Lösung anzupassen, wenn neue Technologie verfügbar wird. So können Nutzer bequem und kostengünstig vom schnellen Fortschritt in der KI-Forschung profitieren.
Die modulare Struktur erlaubt die einfache Anpassung an die doch meist recht individuellen Umstände und Anforderungen jedes Kunden. Zudem erleichtert sie es, die Lösung anzupassen, wenn neue Technologie verfügbar wird. So können Nutzer bequem und kostengünstig vom schnellen Fortschritt in der KI-Forschung profitieren.
4. Bestellannahme mit paipz® von weyp
4.1. Die Eigenheiten von Bestellungen und Abbildung in paipz
Für den in [1] beschriebenen konkreten Einsatz wurde folgende Konfiguration verwendet. Das Eingabemodul ist mit dem (recht speziellen) E-Mail-System des Kunden verbunden. Er analysiert die Haupttext jeder E-Mail sowie die Anhänge, die potenziell Bestellinformationen enthalten. E-Mails mit anderen Anliegen als Bestellungen werden erkannt und „abgelehnt“ (also nicht im paipz-Modul „Bestellungen“ weiterverarbeitet – die Bearbeitung durch ein anderes Modul wäre aber natürlich möglich).
Die Bestellungen selbst werden nach Dateiformaten getrennt analysiert. Das wichtigste Format, mit circa zwei Dritteln des Volumens, ist PDF. Darin sind die Informationen quasi immer entsprechend einem typischen Brief semi-strukturiert:
- Die Identität des Bestellers (Firma, Kontaktperson, Adresse) steht oben im „Absender-Feld“.
- Bestellnummer, Lieferadresse, Datum und dergleichen sind manchmal tabellarisch gruppiert, manchmal über die Seite(n) verteilt.
- Die bestellten Artikel selbst sind als Tabelle aufgeführt. Dabei variiert allerdings die Auswahl, Bezeichnung und Anordnung der Spalten.
Dementsprechend setzen wir unterschiedliche Technologien ein, um die jeweiligen Informationen zu finden und zu extrahieren. So lässt sich z.B. das Adressfeld mit einer sehr „kleinen“, spezialisierten KI zuverlässig finden – sehr viel kostengünstiger und zudem zuverlässiger als LLMs. Die feinteilige Strukturierung der enthaltenen Informationen geschieht wiederum weitgehend mit klassischer Informatik.
Man könnte denken, dass die Darstellung der Artikel als Tabelle deren Extraktion besonders einfach macht. Doch das Gegenteil ist der Fall, wie wir gleich sehen werden.
4.2. Herausforderungen am Beispiel: Tabellenextraktion
Wie oben bereits beschrieben, weisen die Tabellen eine hohe inhaltliche Variabilität auf. Es kommt also darauf an zu erkennen, welche Spalte welche Informationen enthält. Ob z.B. eine Spalte namens „Artikel“ eine Artikelnummer (EAN? Oder die Nummer im Firmenkatalog?) enthält, oder einen Namen des Artikels (Offizielle Bezeichnung oder informelle Variante? Mit Herstellername oder ohne? Deutsch oder englisch?).
Dabei hilft KI – konkret haben sich z.B. moderne LLMs als sehr hilfreich dafür erwiesen, auch weil sie ohne aufwändige Anpassungen für diverse Anwendungsfälle eingesetzt werden können. Bevor solche universell vortrainierten LLMs verfügbar waren, haben wir stärker spezialisierte KI-Modelle eingesetzt, die allerdings nur für jeweils einen Anwendungsfall trainiert wurden und kompetent waren.
Doch die Schwierigkeiten mit Tabellen fangen früher an. Hier ist eine (unvollständige) Liste von Teilproblemen, die gelöst werden müssen:
- Erkennung der Tabellen im Dokument; Unterscheidung von ähnlich wirkenden Strukturen mit anderer Semantik
- Erkennung von Substrukturen: Zeilen, Spalten, Spaltentitel, Zeilenblöcke, Zellen, vereinigte Zellen
- mehrzeilige Zellen
- korrekter Umgang mit „unkonventionellen“ Strukturen, z.B.
- einander überlappende Spalten
- Spalten mit mehreren, untereinander angeordneten Feldern
- „Tabellen in Tabellen“: der Inhalt von Zellen ist in sich tabellarisch organisiert
- Seitenumbrüche innerhalb der Tabelle oder gar innerhalb einer Tabellenzeile
Bei Bestelleingängen sehen wir alle diese Herausforderungen (und noch mehr); die Autoren sind oft erstaunlich kreativ. Zur Illustration folgt zwei reale Beispiele aus dem Bestelleingang eines unserer Kunden.
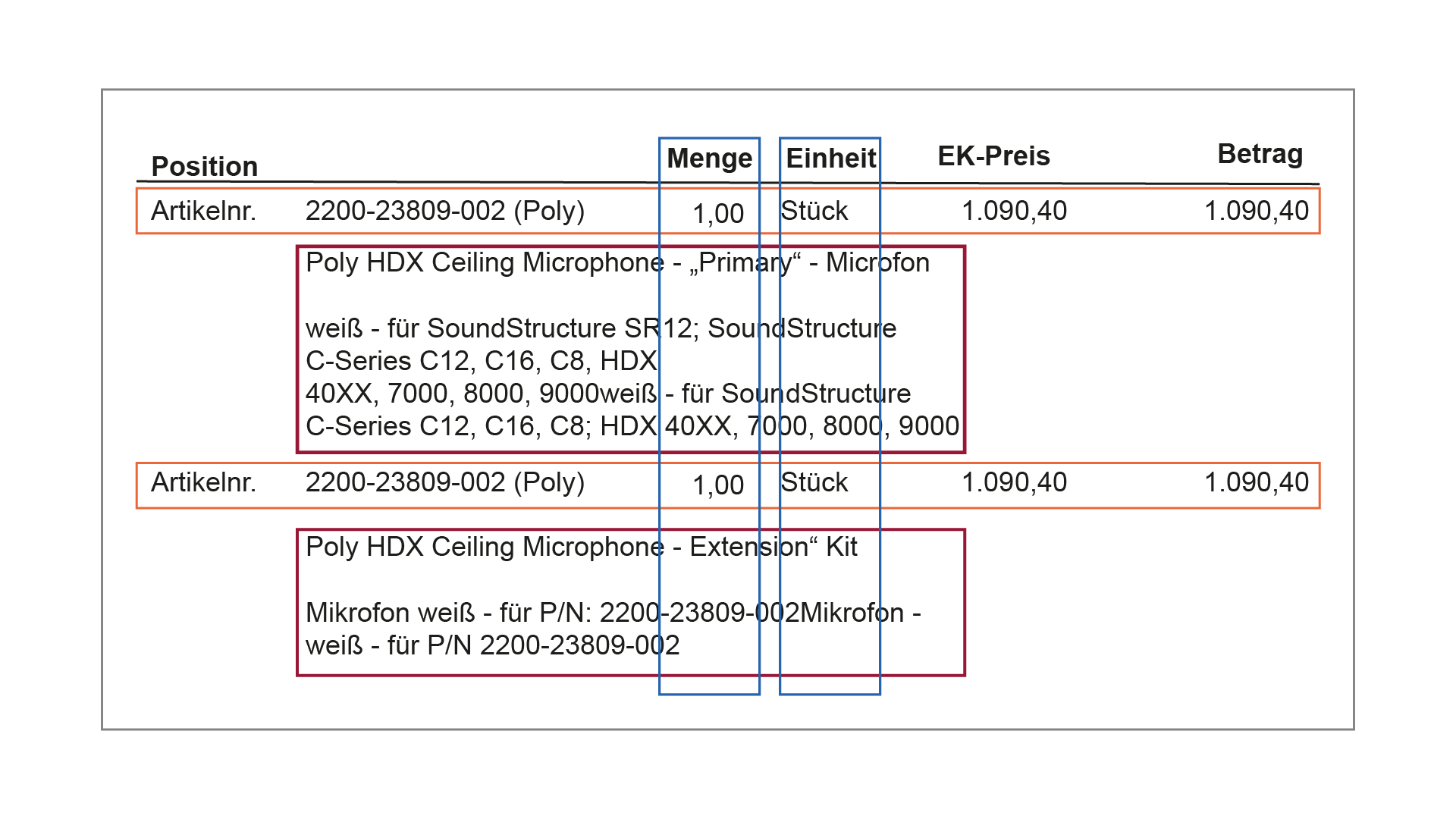
Was auf den ersten Blick aussieht wie eine normale Tabelle, weicht in mindestens vier Punkten von einer klaren, gitterartigen Struktur mit Spaltenbenennung ab. Angabe der Position fehlt, trotz entsprechend benannter Spalte. Spalten für Artikelnummer und –bezeichnung hingegen existieren, sind aber nicht benannt. Die Artikelbezeichnungen laufen in die Spalten für Menge und Einheit. Schließlich sind die „Spalten“ für Artikelnummer und –bezeichnung eher untereinander als nebeneinander angeordnet.
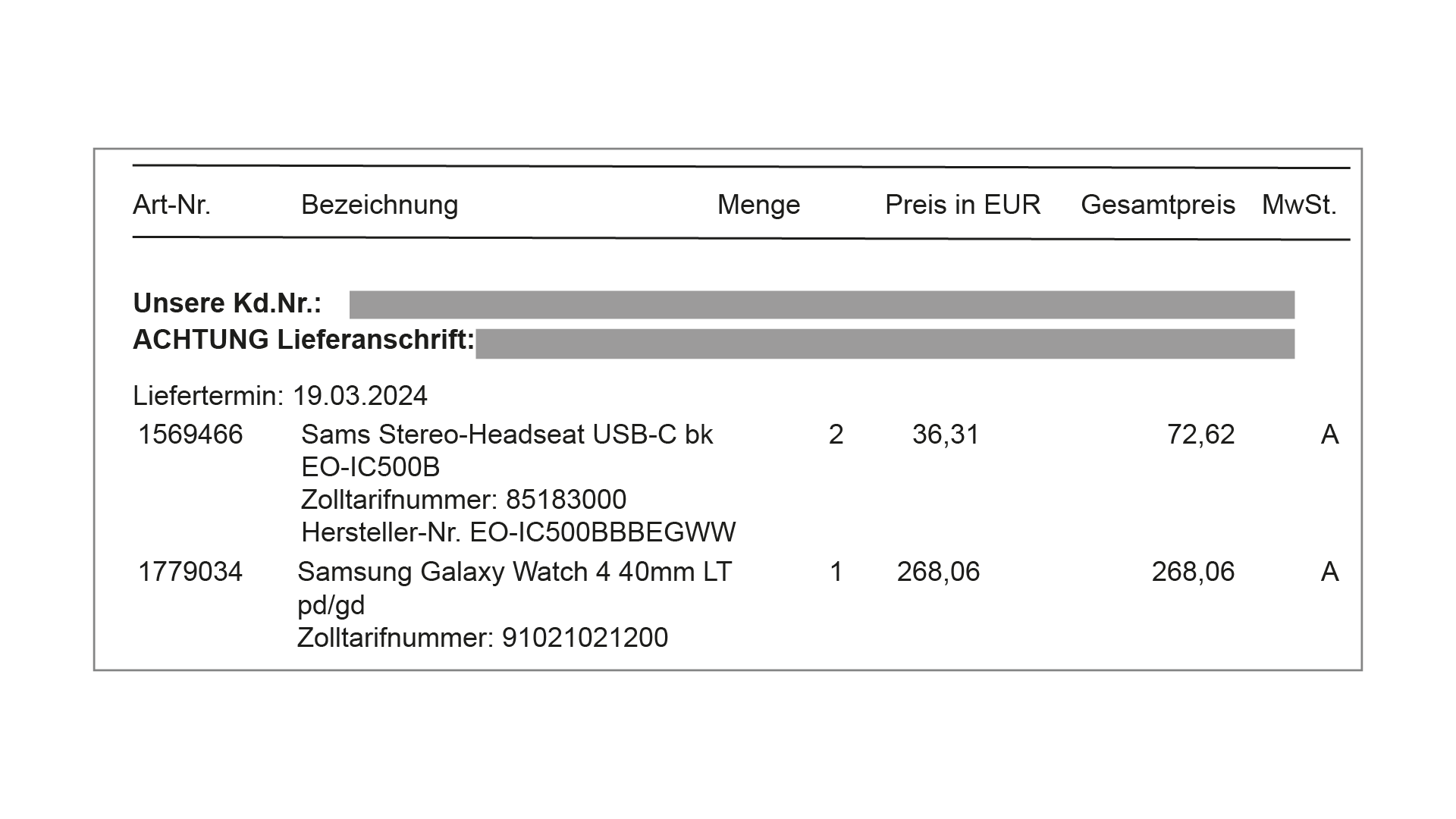
Im zweiten Beispiel ist die Tabelle durch Informationen zur Lieferung unterbrochen. Wegen solcher Probleme, die in einer schlecht vorhersehbaren Vielzahl von Variationen auftauchen, scheitern „klassisch“ programmierte Algorithmen zur Tabellenextraktion (wie z.B. die Python-Bibliothek „camelot“ oder „tabula“) regelmäßig in der Praxis.
4.3. Technologie am Beispiel: Tabellenerkennung
Beispielhaft gehen wir im Folgenden für die Erkennung von Tabellen etwas detaillierter auf unsere Technologie ein: Zunächst muss eine Tabelle als solche erkannt bzw. lokalisiert werden. Dafür sind verschiedene Ansätze denkbar und, je nach konkretem Dokument, geeignet. Unsere Mitarbeiter haben u.a. ein Verfahren entwickelt, das auf Bildverarbeitung (computer vision, CV) basiert, sowie eins, das rein textuell (mithilfe eines LLMs) arbeitet.
Der Bildverarbeitungsansatz ist recht allgemein: er lässt sich auch für die Erkennung anderer gestalterischer Elemente in Dokumenten verwenden, z.B. Graphiken, Überschriften, Absätze. Dazu werden viele Beispiele solcher Elemente in einem Korpus von Dokumenten virtuell markiert, indem ein Rechteck um sie herumgezogen wird. Dann wird ein etabliertes Modell für visuelle Erkennung auf diesen Daten trainiert. Die besten Modelle sind heutzutage „convolutional neural networks“ (CNNs) oder „detection transformers“ (DETR). Wir verwenden CNNs aus der „YOLO“-Serie [3], mit denen wir sehr hohe Genauigkeit bei moderatem Verbrauch an Rechenleistung erzielen.
Auch LLMs sind vielseitig einsetzbar, aber die Verarbeitung von Tabellen erfordert oft einige zusätzliche Arbeit (z.B. [4]). Eine Schlüsseltechnologie dazu ist „RAG“ (retrieval-augmented generation), mit der der LLM gezielt die Dokumente oder Dokumentfragmente zur Verfügung gestellt werden, die zur Beantwortung einer Frage nötig sind. Zum eine kann das „Halluzinationen“ verhindern, mit denen das LLM Lücken in seiner Wissensbasis füllt. Im Zusammenhang mit Tabellen ist aber vor allem wichtig, dass mit RAG auf der anderen Seite auch viel irrelevante Information weggelassen werden kann. Solche Information kann ein LLM leicht „ablenken“ oder „verwirren“, also zu schlechten oder falschen Antworten führen. Es ist daher oft sinnvoll, ein Dokument in Abschnitte zu zerlegen, und dem LLM nur eine Tabelle als Eingabe zuzuführen, um Daten aus dieser Tabelle zu extrahieren. Doch auch dann sind LLMs eher dafür geeignet, gezielt einzelne Werte aus der Tabelle heranzuziehen. Bei der Bestellannahme, wie auch bei vielen anderen Anwendungen, ist es aber erforderlich, die Tabelle als Ganzes für die symbolische Verarbeitung aufzubereiten. weyp hat daher einen eigenen Ansatz entwickelt, der dies mit Hilfe von LLMs umsetzt.
Je nach Art des Dokuments, Gestalt der Tabelle, Sprache und Bedeutung der Inhalte sowie Anforderungen aus der Anwendung kann der eine oder der andere Ansatz geeigneter sein. Um maximale Automatisierung und Zuverlässigkeit zu erreichen, lassen sich sogar mehrere Ansätze kombinieren. Dabei sind die Konfidenzen extrem hilfreich.
5. Konklusionen
Zusammenfassend können wir folgende Erkenntnisse festhalten:
- Das Extrahieren strukturierter Daten aus Dokumenten ist nicht gut mit chatGPT oder ähnlichen generativen Sprachmodellen (allein) lösbar.
- Stattdessen empfiehlt es sich, verschiedene Arten von KI (analytisch und generativ; Sprachmodelle und Bildverarbeitung) sowie symbolische (klassische) Algorithmen zu kombinieren.
- Alle Algorithmen müssen die Zuverlässigkeit ihrer Resultate quantifizieren (mit „Konfidenzen“ versehen); bei Zweifeln müssen sie bequem von Menschen geprüft werden können.
- Breite Einsatzfähigkeit und Zukunftsoffenheit werden durch eine modulare Architektur ermöglicht.
So können Prozesse automatisiert, Mitarbeiter entlastet, und Nutzern und Kunden weiterhin die erforderliche hohe Qualität geboten werden.
6. Referenzen
- Efficient order processing: from manual processes to AI-supported automation; 2024. https://medium.com/@harmonious_beige_minnow_591/document-understanding-order-management-ded1e8689d57
- Paipz; 2024. https://paipz.de
- YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors; 2022. https://arxiv.org/abs/2207.02696
- PDF Hell and Practical RAG Applications, 2024. https://unstract.com/blog/pdf-hell-and-practical-rag-applications/

13 Comments